

欢迎进入某某教育官方网站!
咨询热线:400-123-4567

欢迎进入某某教育官方网站!
咨询热线:400-123-4567

PgSQL · 源码分析 · PG优化器物理查询优化
发布时间:2024-04-22 15:04:31
在之前的一篇月报中,我们已经简单地分析过PG的优化器(PgSQL · 源码分析 · PG优化器浅析),着重分析了SQL逻辑优化,也就是尽量对SQL进行等价或者推倒变换,以达到更有效率的执行计划。本次月报将会深入分析PG优化器原理,着重物理查询优化,包括表的扫描方式选择、多表组合方式、多表组合顺序等。
表扫描方式主要包含顺序扫描、索引扫描以及Tid扫描等方式,不同的扫描方式
全表扫描时每条记录都会返回,所以选择度为1,所以rows=10000
备注:如果值不在most_common_vals里面,计算公式为:
代价模型:总代价=CPU代价+IO代价+启动代价
总cost=cpu_tuple_cost * 952 + seq_page_cost * 5 + cpu_operator_cost * 952
=16.90
其他扫描方式cost计算可以参考如下函数:
假设:
M=20000 pages in L, pL=40 rows per page,
N=400 pages in R, pR=20 rows per page.
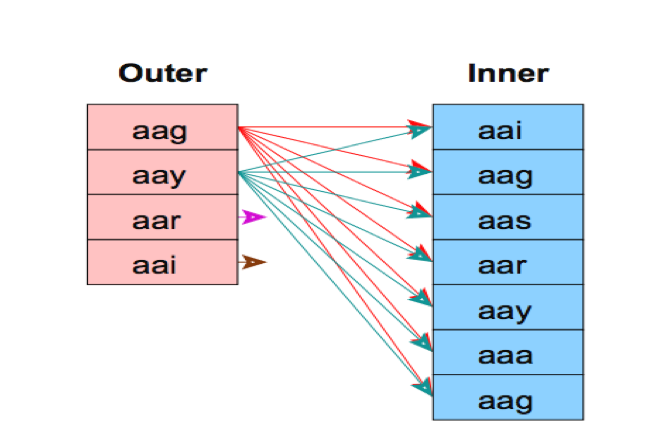
L和R进行join
对于外表L每一个元组扫描内表R所有的元组
总IO代价: M + (pL * M) * N=20000 + (4020000)400
=320020000

主要分为3步:
(1) Sort L on lid 代价MlogM
(2) Sort R on rid 代价NlogN
(3) Merge the sorted L and R on lid and rid 代价M+N
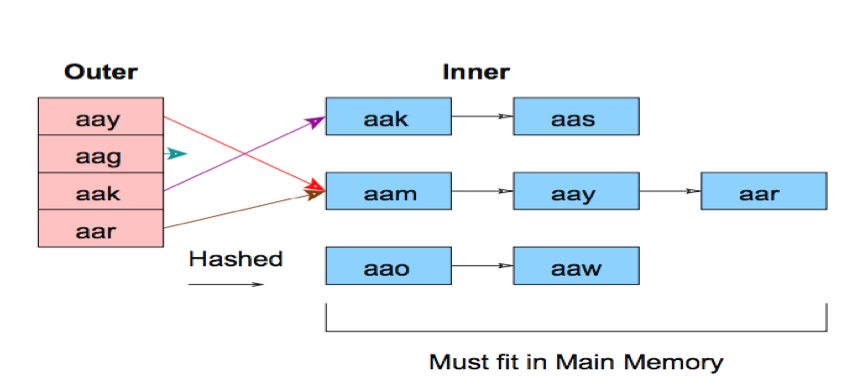
使用HashJoin的前提是其中假设一个表可以完全放在内存中,实际过程中可能统计信息有偏差,优化器认为一个表可以放到内存中,事实上数据在内存中放不下,需要使用临时文件,这样会降低性能。
不同的组合顺序将会产生不同的代价,想要获得最佳的组合顺序,如果枚举所有组合顺序,那么将会有N!的排列组合,计算量对于优化器来说难以承受。PG优化器使用两种算法计算更优的组合顺序,动态规划和遗传算法。对于连接比较少的情况使用动态规划,否则使用遗传算法。
PG优化器主要考虑将执行计划树生成以下三种形式:
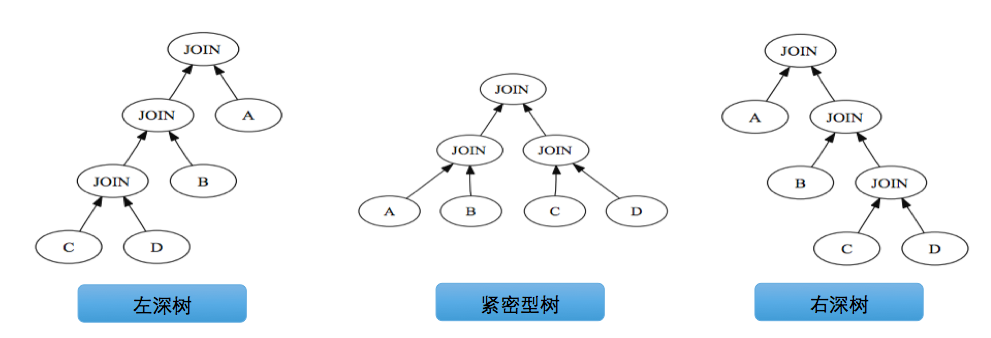
动态规划的思想可以参考百度百科动态规划,主要将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到原问题的解。具体应用在表组合顺序上,则是先考虑单表最优访问访问,然后考虑两种组合,再考虑多表组合,最终得到更优的解。




